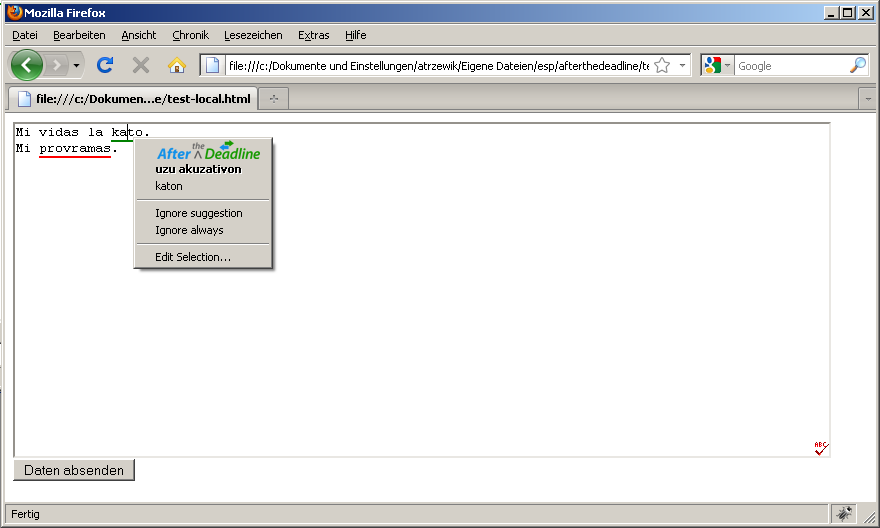
Esperantilo enhavas bazon de vortoj kun iliaj kuntekstoj (vidu menuo: Lingvistiko-Bazo de Frazpartoj).
La bazo estas kreita de granda esperanta tekstaro.
La kuntekstoj estas ordigitaj laŭ gramatika dependeco. Do oni povas trovi ekzemple, kiuj adjektivoj priskribas iun substantivon.
Ekzemplo por vorto „patro“:
np np-adj
cikonia (25), sankta (24), bona (8), kara (6), alia (5), malfeliĉa (5), malbona (4), maljuna (4), propra (4), adoptinta (3), cia (3), mortinta (3), prava (3), respektinda (3), sama (3), ĉiela (3), malsana (2), nuna (2), pia (2), senmorta (2), vera (2), dia (1), estinta (1), estonta (1), feliĉa (1), fiera (1), filiniginta (1), flama (1), forlasita (1), formortinta (1), gajninta (1), granda (1), ideala (1), ironta (1), juna (1), kontenta (1), kruela (1), laŭlega (1), laŭnatura (1), libera (1), malafabla (1), malnaturigita (1), natura (1), needziĝinta (1), proksima (1), ruĝhara (1), sana (1), saĝa (1), spirita (1), stulta (1), suna (1), vivanta (1), ĵusa (1)
obj vp-obj
havi (17), ami (8), demandi (4), simili (3), trovi (3), koni (2), rigardi (2), vidi (2), viziti (2), peti (2), timi (2), kovri (1), ekvidi (1), doni (1), respekti (1), kaŝrigardeti (1), nomi (1), rigardadi (1), ricevi (1), indulgi (1), anstataŭi (1), trompi (1), esperantigi (1), kontentigi (1), instigi (1), kuŝi (1), inciti (1), kisi (1), adiaŭi (1), povi (1), malobei (1), murdi (1), meti (1), impresi (1), eniri (1), transporti (1), postuli (1), rekoni (1), spiti (1)
subj vp-subj
esti (74), diri (59), veni (13), havi (11), povi (10), morti (10), fari (8), demandi (8), respondi (7), doni (5), voli (5), rigardi (5), rakonti (4), loĝi (4), dormi (4), ekkrii (4), nomi (3), komenci (3), devi (3), posedi (3), labori (3), reveni (3), scii (3), preni (3), akcepti (3), alporti (2), stari (2), ordoni (2), turni (2), aŭskulti (2), akompani (2), iri (2), aĉeti (2), fariĝi (2), promesi (2), paroli (2), ekvidi (2), ĵeti (2), kuŝi (2), kompreni (2), mencii (2), timi (2), plendi (1), ekplori (1), sidiĝi (1), aparteni (1), ekridi (1), forveturi (1), ekinstrui (1), konsili (1), demeti (1), aserti (1), ekzameni (1), rekomenci (1), donaci (1), agi (1), flugi (1), provi (1), ami (1), balanci (1), peti (1), rajdadi (1), konigi (1), etendi (1), trafi (1), diradi (1), ekloĝi (1), surprizi (1), montriĝi (1), iĝi (1), difini (1), fali (1), ŝerci (1), planti (1), observi (1), vivi (1), ekmiregi (1), humiliĝi (1), elekti (1), vendi (1), lasi (1), ektimi (1), preterpasi (1), plaĉi (1), legi (1), fidi (1), eksilenti (1), plenumi (1), ŝajni (1), levi (1), verki (1), prunti (1), enveni (1), certigi (1), ĉagreniĝi (1), ricevi (1), pentri (1), bruligi (1), ploraĉi (1), interparoli (1), malŝati (1)
sub vp-pp-sub
iri al (6), esti por (3), ricevi de (3), ĵuri al (2), veni al (2), fari por (2), fariĝi al (2), promesi al (2), esti de (2), esti kun (2), sendi al (2), heredi de (2), paroli pri (2), skribi al (2), eltrinki al (1), alporti al (1), stari apud (1), okazi al (1), fantazii pri (1), rapidi al (1), rapidi post (1), draŝi al (1), agi kun (1), veni je (1), veni kun (1), kortuŝi al (1), kvereli kun (1), stariĝi apud (1), fari de (1), iri kun (1), loĝi ĉe (1), lasi al (1), fariĝi de (1), elmezuri por (1), reveni al (1), levi al (1), prunti de (1), serĉi de (1), esti al (1), esti pri (1), regi de (1), persekuti de (1), interparoli kun (1), proksimiĝi al (1), havi kun (1), anonci al (1), ekpensi pri (1), akiri por (1), ludi de (1), ludi ĉe (1), diferenci de (1), pensi pri (1), verŝi al (1), ripeti al (1), renkontiĝi kun (1), kompreni al (1), bori kun (1), demandi al (1), ĉeesti kun (1)
sub sub-pp-sub2
de infano (9), de arne (3), de knabo (3), de maŭrico (3), de antono (2), de edzino (2), de fernando (2), de filo (2), de kristino (2), de amikino (1), de andreo (1), de anjo (1), de cindrulino (1), de familio (1), de georgo (1), de ido (1), de johano (1), de josefino (1), de junulo (1), de knabineto (1), de kristoforo (1), de lumo (1), de markizo (1), de matildo (1), de petro (1), de reĝido (1), de reĝino (1), de sfinkso (1), kun filo (1), kun voĉo (1)
sub2 sub-pp-sub2
palaco de (9), tombo de (6), domo de (4), volo de (3), alveno de (3), morto de (3), nomo de (2), ordono de (2), vizaĝo de (2), enterigo de (2), spirito de (2), kastelo de (2), kolo de (2), koro de (2), kolero de (2), bieno de (2), portreto de (2), amemo de (1), aspekto de (1), bildo de (1), forveturo de (1), amiko de (1), insistemo de (1), diro de (1), apudestado de (1), ago de (1), nombro da (1), laboro de (1), infano de (1), ĉapelo de (1), emo de (1), si de (1), edzino de (1), kadavro de (1), brandujo de (1), vorto de (1), kamarado de (1), rikoltisto de (1), voĉo de (1), vivo de (1), oficejo de (1), vizito de (1), ombro de (1), okulo de (1), vidpunkto de (1), brako de (1), renkonto kun (1), pereigo de (1), interparolo kun (1), lito de (1), mano de (1), gajno de (1), ĝi de (1), bato de (1), sledeto de (1), sinteno de (1), konduto de (1), letero de (1), korpo de (1), ĝojo de (1), restaĵo de (1), rolo de (1), edziniĝo kun (1), frenezaĵo de (1), seĝo de (1), heredaĵo de (1), trezorejo de (1), frato de (1), foriro de (1), tero de (1), kutimo de (1), virino de (1)
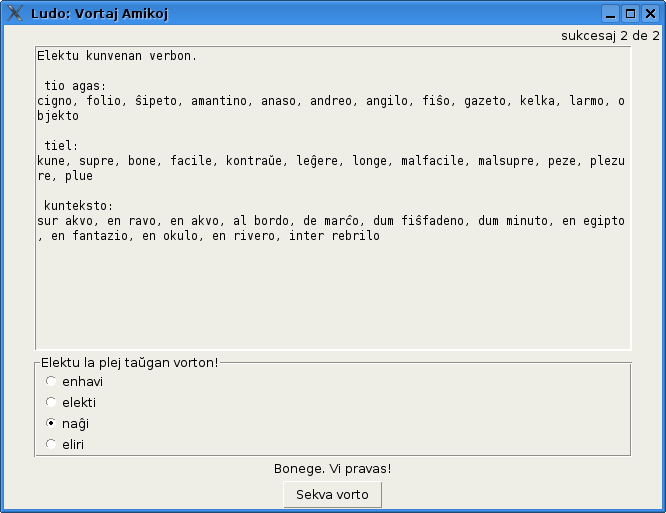
Mi trovis, ke oni povas diveni la vorton „patro“, nur de la kono de kuntekstoj. Tio estas la ideo de la ludo. Dum la ludo oni vidas nur la kuntekstajn vortojn (amikoj de vortoj) kaj devas elekti el la listo de 4 vortoj la konvenan vorton. La amikaj vortoj estas ordigitaj laŭ ofteco kaj estas montritaj nur plej facilaj gramatikaj dependecoj. La ludanto devas dum unu ludo diveni 10 vortojn (substativojn, adjektivojn aŭ verbojn). Vortoj estas elektitaj hazarde. Por ke la ludo ne estu tro malfacila, la ludanto devas diveni nur oftajn vortojn. La ludo estas nun la parto de programo esperantilo (de eldono 0.990) kaj estas atingebla per menuo (Lingvistiko/Ludo Vortaj Amikoj).
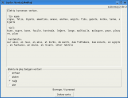
La ludo ne estas facila kaj oni devas bone koni la lingvon. Tamen mi jam sukcesis diveni 10 ĝustajn respondojn. Iam okazas, ke la hazarde elektitaj vortoj por la elekto estas tre similaj, tiam la ludo enhavas hazardan elementon, ĉar oni ne estas eble elekti la ĝustan vorton nur de bona kono de lingvo.
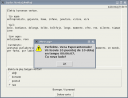
Mi pensas, ke la ludo estas interesa, ĉar oni ekkonas per tiu ludo la veran uzadon de vortoj, kiu devenas de granda esperanta tekstaro. Tiuj kuntekstoj estas ofte pensigaj kaj surprizaj.
Bonan Ludadon!