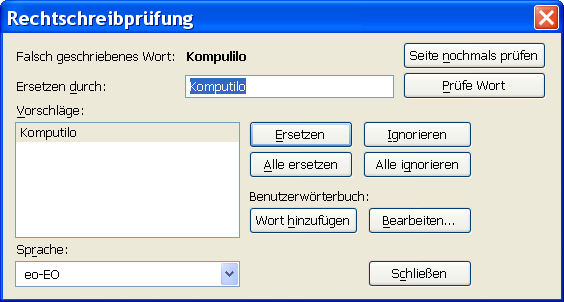
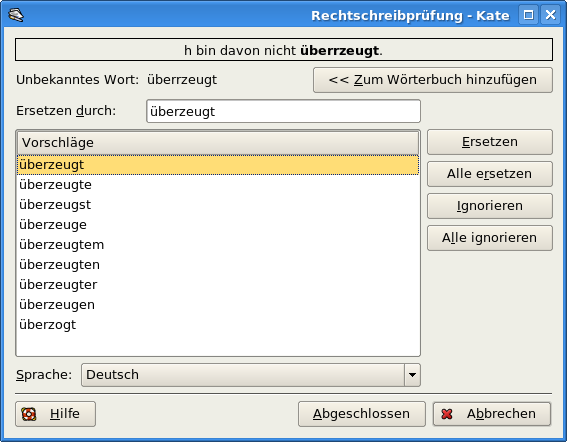
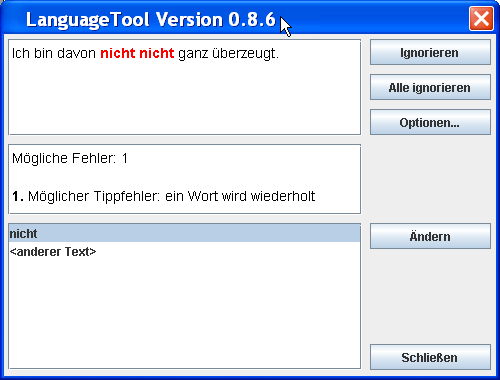
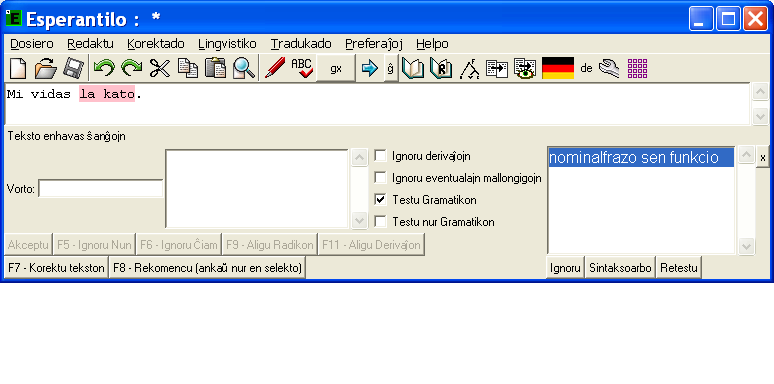
Vorteto „unu“ estas uzata en Esperanto en multaj funkcioj. Funkcioj de tiu vorteto ne limigas nur al tiuj de numeralo. Ni vidu la ekzemplojn:
- Mi havas unu libron.
- Ili venis unu post la alia.
- Unu faras tion, la alia faras la alion.
- Unuj ne konas tiun problemon.
En la tri lastaj ekzemploj ‚unu‘ estas uzata ne kiel numeralo sed kiel pronomo. Oni rapide tion povas konstati, se oni pripensu la ekzemplojn kun aliaj numeraloj. Ne ekzistas ja formoj: duj, dun, dujn. Tiu malkonsekvenco ofte ĝenis kelkajn Esperantistojn, do ili konstatis tiun uzadon kiel eraro. Iu Esperantistino, kiu konsilis min pri lingvo dum frua programado kaj kolektis la unuajn ekzemplojn de eraroj en lingvo esperanto, ankaŭ aldonis ‚unuj‘ kiel falsa uzado. Tiam mi jam asertis, ke ‚unuj‘ ŝajas esti kutima vorto en esperantaj tekstoj. La respondo estis tre rigida: „Ankaŭ se iu vorto estas ofte uzata, tio ne signifas, ke ĝi ne estas erara“. Poste la saman ekzemplon konstatis la alia Esperantisto (kreinto de fama PMEG) kiel tute korekta (vidu Diskutejo: „Komputila Lingvistiko“). Interesa en tiu diskutejo estas ankaŭ la mencio de analiza skolo: (citaĵo: „Mi konstatas, ke iu legis tro da libroj de la ‚Analiza Skolo'“). Verdire mi antaŭe nenion sciis pri ‚analiza skolo‘, kvankam mi mem delonge supozis multajn skolojn de esperantaj lingvistoj.
Dum kontaktoj kun multaj Esperantistoj mi ofte spertis, ke ili ofte proponas kaj asertas tute kontraŭajn konsilojn. Mi ne volas partopreni en la diskutoj de tiuj skoloj, sed mi sentas min kiel simpla uzanto de la lingvo kaptita inter multaj frontoj.
Mia tendenco de aliro al tiuj problemoj estas nuntempe statistika aŭ naturisma. La ĉefa (precipa) kazo de tio estas, ke mia programo devas analizi esperantajn tekstojn. Se mi ne akceptas kelkajn formojn, la programo malsukcesis korekte analizi (do traduki) la tekstojn. Ankaŭ se mia granda deziro estus, ke esperanta lingvo estus regula kaj logika, mi devas akcepti la realon de ekzistantaj esperantaj tekstoj. Tio estas ofte tre ĝena afero, ĉar kun ĉiu mallogika escepto la programado plimalfaciligas kaj la rezultoj de maŝina tradukado estas malpli bonaj.
Kvankam esperanto estas kreita lingvo, nun oni ne povas altrudi la regulojn de uzado al la uzantoj. Uzantoj de lingvo mem kreas ĝiajn regulojn. Evidente, post kiam la lingvo estis kreita kaj oni ĝin uzas, oni ne povus diri pri planita lingvo sed jam natura lingvo.
Reguloj de Esperanto
La plej gravaj reguloj de esperanto estas enskribitaj en unu dokumento, kion oni nomas „La Fundamento“. La Fundamento havas por esperantistoj preskaŭ sanktan signifon. Ĝi estas ofte prezentata kiel enkorpigo de reguleco, klareco kaj facileco de la lingvo. Sed se oni pensu ne pri tio, kion la fundamento diras, sed pri tio, kion la fundamento ne diras, la rezultoj de tiu dokumento estas magraj. Ĉu vere 16 reguloj povus esti sufiĉaj pro difini la lingvon aŭ eĉ ĝian fundamenton?
La fundamento diras nenion pri sintakso de lingvo. Oni vene serĉas informojn pri interpunkcio kaj aliaj gravaj reguloj. Mi pensas, ke ankaŭ Zamenhofo sciis pri tiu neebleco difini klarajn regulojn. Li do kreis longajn kelkspecajn tekstojn por doni ekzemplojn de ĝia uzado. En tiuj ekzemploj li uzis la vortetojn „unuj“. Kaj tie kuŝas la problemo. Tiu formo eble ne estas avantaĝa kaj ŝajne escepta, sed la majstro ĝin uzis. Ĉar la majstro ĝin uzis, ĝi estas la parto de lingvo.
Aliaj reguloj iom post iom kreiĝis de unuaj uzantoj de esperanto. Ili baziĝas sur heredaĵo de iliaj lingvoj, eŭropaj lingvoj. Multe pli tio, kio la Fundamento ne diras, oni hipotezas kiel kutima por aliaj lingvoj (lingvoj de kelkaj nacioj). Ĉu vere oni do povas nomi Esperanton la planita lingvo?
Malreguleco kiel ŝajna avantaĝo de Esperanto
Ne ekzistas neniu regulo pro tio, kiu suba frazo estas korekta:
- Mi helpas al vi.
- Mi helpas vin.
- Mi dankas pro tio.
- Mi helpas per tio.
- Mi helpas je tio.
Ĉiu, kiu lernis iun fremdan lingvon, scias, ke oni lernu ankaŭ ne nur verbojn sed ankaŭ konvenajn prepoziciojn uzataj kun tiuj verboj.
Esperantaj lernolibroj diras, ke oni havas liberan elekton de iu formo. Ĉiuj estas korektaj. Tio estas tre kontentiga informo por lernantoj.
Esperanto estas tre juna lingvo. Kiel aspektos tiu kutimo en sekvaj jaroj? Se oni observis la evoluon de naturaj lingvoj, oni devas konstati, ke la naturaj lingvoj ne akceptas plurajn formojn, kaj finfine unu formo supervenkas la alian. Laŭ tiu principo kreiĝas dialektoj kaj poste tute aliaj lingvoj. Do tiu libereco estas nur portempa. Iam kelkaj nuntempaj frazoj sonas por venontaj Esperantistoj (se ili estos) tiel strange, kiel nun por Poloj sonas maljunaj polaj libroj.
Esperanto kiel venonta plej malfacila lingvo de mondo
La esperanta lingvo evoluas kaj ŝanĝiĝas (aliaj dirus, ke ĝi pliriĉiĝas). La nuna praktiko estas, ke ĉiu uzas la lingvon laŭ propraj manieroj de gepatra lingvo. Klareco kaj logiko ne estas gravaj. Tio nepre kondukos al la stato, ke Esperanto enhavos la strukturojn kaj lingvajn kutimojn de multaj tre diferencaj lingvoj. Ankaŭ la malfacileco de angla lingvo rezultas de multaj influoj de aliaj lingvoj. La angla lingvo estas miksaĵo de kelkaj lingvoj, kaj tiel ĝi estas malfacila.
Iu germano diris: Angla lingvo estas samtempe facila kaj malfacila. Ĝi estas facila, ĉar ĝi konsistigas nur de fremdvortoj. Samtempe ĝi estas malfacila, ĉar ĉiuj tiuj vortoj estas malkorekte elparolataj.
Mi ofte trovas en Esperanto strukturojn de pola, germana kaj rusa lingvoj. Mi ofte miras pri lingvaĵo de azianaj Esperantistoj. Mi komprenas ion, sed ĉio estas stranga. Ofte esperantaj tekstoj estas tiel malkaraj kaj malkompreneblaj, ke mi devas rezigni pri la legado. Esperantistoj estas ankaŭ kreemaj personoj, kaj elpensas ofte novajn strukturojn. Tial la legado de esperantaj tekstoj oni povus kompari al matematikaj ludoj aŭ ludaj enigmoj (simile kiel SUDOKU). Laŭ moto: Uzanto, deenigmu la signifon kaj admiru mian povon de kreado, scion de lingvo kaj lertecon de ĝia uzado!
Ĉar Esperanto estas tre juna (en tempomezuro de lingvoj), la influo de aliaj lingvoj sur Esperanto estas tre granda. Nur firmaj naciaj lingvoj havas ŝancon konservi ĝian eĉ pli malgrandan regulecon. Manko de reguloj kondukas nepre al venonta malreguleco.
Deveno de plurfunkcia uzado de ‚unu‘
Uzadon de ‚unu‘ en alia signifo ol numeralo mi konas de pola kaj germana lingvo. En germana lingvo ‚unu‘ rolas eĉ aldonan funkcion kiel nedifina determinilo (artikolo). Mi pensas, ke la uzado fontas ĉefe en pola lingvo.
- Ili venis unu post alia.
- Oni przychodzili jeden por drugim. (pole)
- Sie sind nacheinander gekommen. (germane)
- Они пришли друг за другам. (ruse)
- Unu volas tion, la alia volas la alion.
- Jeden chce to, a drugi tamto. (pole)
- Einer will das, der andere will aber das. (germane)
- Один хочеть … (ruse)
- Unuj ne siac tion.
- Jedni o tym nie wiedzą. (pole)
- Einigen wissen das nicht. (germane)
- Одни этово не знают. (ruse)
- Unuj homoj …
- Jedni ludzie … (pole)
- Einige leute … (germane)
- Одни люди … (ruse)
La germana lingvo havas apartan formon por „unuj“ – „einige“. Ial supriza estas la rusa formo por „unu post alia“, kiu direkte tradukita estas „amiko post amiko“. La germana formo „nacheinander“ astas de kunligo de „nach ein ander“ – do „post unu alia“. Tiu solvo estas tre interesa, ĉar tiun vorton tuj oni povas konsideri kiel adverbo. (mi pensas pri novesperantaj vortoj kiel: surkovrilpaĝe). Do aliaj lingvoj solvas parte tiun problemon sen uzo de „unu“. Nur pola lingvo uzas konsekvence „unu“ por ĉiuj tiuj kazoj.
Fina konstato
Mi iom post iom (novesperante: poiome) akceptas sendiskute ĉion, kion mi frontas en esperantaj tekstoj. Mi ne volas krei tiun lingvon, sed mi volas nur ĝin uzi. Se mi serĉas respondojn kaj regulojn, tiujn povas doni al mi nur statistiko. Decidoj de akademio de Esperanto estas tre maloftaj, kvazaŭ la lingvo tiujn decidoj (do regulojn) ne necesus kaj ĉio estus klara. La stato ne estas do alia ol ĉe naciaj lingvoj. Ĝi estas eĉ pli malbona, ĉar la lingvo estas juna kaj Esperantistoj estas tre diferencaj. Tio estas entute la normala afero. Sed, kiam la Esperantistoj ĉesos rakonti fabelojn pri tiu lingvo, ke ĝi estas io tute speciala?