Ideo de maŝina tradukado ekzistas ekde apero de komputiloj. Maŝina tradukado kaj arta penso estis la revo de unuaj programistoj, eble ĉar tiuj temoj estus bone komprenataj por vasta publiko. Tradukado estas malfacila tasko, kiun povas plenumi nur kelkaj homoj post longa lernado. Tial komputilo, kiu tradukas, estus la pruvo por taŭgeco de komputiloj.
Ĉiu nun scias, ke ne ekzistas komputiloj, kiuj povas pensi aŭ traduki en nivelo de homoj. Longe post multaj fiaskaj projektoj, en kiuj oni perdis grandan kvanton de mono, eĉ specialistoj pensis, ke programado de tiuj sistemoj ne estas ebla. Historio de komputika lingvistiko bone priskribas la konata dokumento Machine Translation: past, present, future. Ofte eĉ Esperantistoj varbas por Esperanto kun argumento, ke maŝina tradukado ne estas ebla kaj neniam estos ebla. En tiu kazo oni ofte prezentas tre bizarajn frazojn, kiuj nur tre malfacile estas tradukeblaj eĉ por profesiaj tradukistoj. Mi estas certa, ke per similaj argumentoj oni povus ankaŭ pruvi, ke tradukado ĝenerale ne estas ebla. Sed la temo de komputila lingvistiko ne mortis kaj eĉ lastatempe bone progresas. Kvankam ne ekzistas perfektaj tradukaj programoj, la unuopaj eroj de komputila lingvistiko aperas pli kaj pli ofte. Preskaŭ ĉiu uzas nun literumadon en redaktiloj kaj komputilajn vortarojn. Ankaŭ „google“ estas ja infano de komputila lingvistiko.
Kial fiaskis tiom da projektoj pri maŝina tradukado?
Oni povus ĝenerale diri, ke komputilaj projektoj tre ofte fiaskas. La duono de projektoj neniam finiĝas kaj 75% de projektoj ne atingas la celojn. Ili estas pli multekostaj aŭ ne havas la necesajn planitajn funkciojn. La temo de maŝina tradukado havas aldonojn specialajn trajtojn, kiuj eĉ faras tiujn projektojn eĉ pli malfacilajn kaj pli riskajn. Tio estas:
- Oni havas tre altajn atendojn. Oni volas programojn, kiuj regas multajn lingvojn, tradukas en reala tempo en multaj direktoj kaj povas kompreni diritajn vortojn kaj mem paroli.
- Oni bezonas multajn specialistojn de diversaj kampoj
- La baza lingvistika teorio, kiu estas praktike taŭga, ne ekzistis. La historiaj teorioj ne estis taŭgaj por multaj kazoj.
- Lingvistikaj programaj postulas grandajn necesojn al komputiloj. Ĝis 1980 komputiloj ne estas taŭgaj por lingvistiko, ĉar ili ne havis necesan rapidecon kaj memoron. La haveblaj komputiloj en frua tempo estis tro multekostaj. Oni pripensu, ke eĉ baza vortaro havas 50000 vortojn. Prilabori, traserĉi aŭ redakti tiun kvanton de informoj estas por tiamaj komputiloj tre malfacila tasko.
- La projektoj preskaŭ ĉiam komencis de nulo. Lingvistoj nenion sciis pri komputiloj, programistoj nenion sciis pri lingvistiko. Oni devus skribi programojn kaj solvi bazajn teknikajn defiojn. Lingvistoj devis krei taŭgajn teoriojn.
- Ĉiu profesia projekto havas nur limigitan kvanton da rimedoj. La unua limo estas tempo. Oni devas havi rezultojn post unu aŭ du jaroj. Post tiu tempo la membroj de projekto komencas iom komprenis pri la temo de projekto.
- Tiuj projektoj estis tro grandaj. Organizado de grandaj projektoj estas eĉ pli komplika ol la temo de projektoj. La respondeculoj ofte pensas, ke ĉiu problemo estas solvebla per aldonaj partoprenantoj de projekto. Konata programista anekdoto diras, ke laŭ tiu pensmaniero oni povus konstati: Por havi unu novan homon oni necesus unu virinon kaj 9 monatojn da tempo. Oni povus duonigi la tempon havante du virinojn.
- Ne ekzistis komputilaj materialoj, kiujn oni povis uzi de komenco.
Mi pensas, ke la unua problemo estas, ke la projektoj volis sole atingi ĉion. Oni ne provis dividi la taskon en multaj kampoj. Kvankam projektoj fiaskas, ili ofte lasas multajn rezultojn aŭ eĉ solvojn de unuopaj problemoj. Sed por monaj kaŭzoj estas ofte maleble transdoni tiujn rezultojn al sekvaj projektoj. Do multaj rezultoj malaperas en arkivoj por ĉiam. La projektoj malaperas, kvazaŭ ili neniam estis. En plej bona kazo restas de tiuj projektoj malgranda raporto aŭ scienca laboraĵo, sed vortaroj aŭ programa kodo, ĉio ĉi malaperas por ĉiam.
La unuaj projektoj estis pagitaj de militaj fortoj, ĉar ili bezonis maŝinan tradukadon por spionado de aliaj landoj. Tial la rezultoj de tiuj projektoj estis ŝtataj sekretoj. En universitatoj, kiuj ankaŭ havis lingvistikajn projektojn, oni uzis por projektoj studentojn, kiuj ne estas bonaj spertaj programistoj kaj ofte forlasis la projekton post unu aŭ du jaroj. Tio estas tro mallonga periodo por efike produkti uzeblajn rezultojn. Komercaj projektoj fiaskis miaopinie precipe por kazo de mallonga tempo. Komercistoj pensas precipe nur en unujaraj periodoj de librotenado. Ĝis nun preskaŭ ne ekzistas merkato por partoj de solvoj de komputiko. Tiu kampo de komerca programado laboras laŭ maniero ĉio aŭ nenio. Ĉu iu memoras pri sistemoj kiel Amiga OS, OS/2 aŭ diversaj aliaj programoj, kiuj por ĉiam malaperis, kvankam ĝi rulis bone kaj estis uzeblaj. Ĝis antaŭ mallonga tempo ŝajnis, ke en tiu komerca kampo povas esti nur unu gajninto. Tio estas aŭ IBM aŭ MS. Sed nun ekzistas alia komputila mondo de liberaj programoj. Do estas eble ruli la tutan sistemon nur per libera programaro.
Lingvistikaj projektoj. Ĉu problemo de interkomunikado?
Programistoj kaj lingvistoj devenas el tute aliaj kampoj de scienco. Ili havis alian manieron solvi la problemojn. Mi pensas, ke malbona kunlaboro inter lingvistoj kaj programistoj estas ankaŭ granda kaŭzo de malsukcesoj. Programistoj devenas de scienca kampo de matematiko. Ili serĉis laŭ matematika maniero la mallongan precizan formulon, kiu estas vera por ĉiu kazo. La akademia teorio de lingvistiko estas plena da logikaj formuloj, kiuj preskaŭ malestas en praktika uzo. La naturajn lingvojn oni ne povas priskribi per simplaj formuloj.
En komputilaj projektoj oni kutime havas du grupojn de homoj. La unua grupo estas tiel nomataj teknikaj fakuloj. Tio estas programistoj. Alia grupo estas fakaj specialistoj, kiuj scias iom pri temo de projekto. La sukceso de projekto dependas ofte de ebleco de lernado de du grupoj unu de alia. Programistoj devas lerni de fakuloj kaj fakuloj devas lerni de programistoj.
Lingvistoj devenas de humanecaj sciencoj, simile al filozofio aŭ literaturo. Por ili lingvo estis historie io sakra, io magia, io, kion oni ne nepre devas logike kompreni. Lingvistoj pritraktas lingvojn kun preskaŭ religia maniero. Ili akceptas misterojn kaj nelogikajn esprimojn. Ili ne pruvas. Ili ŝategas debati pri kuriozaĵoj. La argumento de aŭtoritato estas pli grava ol logika pruvo. Lingvistikaj teorioj estis do frue tute maltaŭgaj por programistoj, kiuj devas ja liveri pragmatikajn kaj praktikajn rezultojn. Mi pensas, ke nova generacio de lingvistoj iom post iom lernas uzi sciencajn metodojn en lingvistiko. Ili uzas statistikon, pruvas la rezultojn sur grandaj tekstaroj. Ili lernis ordigi la teorion laŭ ofteco de uzebleco. Kuriozaĵoj ne plu rolas gravan rolon en teorioj. Ili eĉ lernis uzi la komputilon kaj permesas al la aliaj tuŝi ilian sakran lingvon.
Sed ankaŭ la sinteno de programistoj kun rigida matematika fundo estas malutila por lingvistikaj projektoj. Bonan priskribon de takso de programado donas al ni Kulturaj aspektoj de komputil-programado. Programistoj atendis de natura lingvo similajn trajtojn, kiel ili tion konas de programaj lingvoj. Pritrakti naturajn lingvojn estas unue la arto administri esceptojn. Tial oni ne povas atenti iun formulon, kiu priskribas ĉiujn fenomenojn de lingvo.
La kutimaj problemoj, kiujn frontas programistoj, estas ankaŭ aliaj ol tiuj de lingvistiko. Kutime rezultoj de programoj devas esti tre certaj. Oni pripensu komputilaj sistemoj, kiuj de multaj jaroj laboras en bankoj aŭ en komerco. Komputiloj regulas multajn sistemojn. Ili konservas grandajn datumojn. Ili devas esti sekuraj kaj certaj. En lingvistiko, la problemoj estas ofte ne certaj. La problemoj havas statistikan naturon. En komputiko, ĉiu esprimo estas aŭ vera aŭ malvera. Naturaj lingvoj ne havas tiujn trajtojn. Tial lingvistikaj programoj devas prilabori datojn, kiuj enhavas erarojn, kiuj ne estas tute analizeblaj. Rezultojn de maŝina tradukado oni nur malfacile povas pritaksi, ĉar eĉ tradukoj de homoj estas diskuteblaj. Ne ekzistas objektiva mezuro de kvalito de tradukado.
Natura lingvo sekvas la statistikajn principojn de naturaj fenomenoj. Ekzemple oni povas kun 10 simplaj reguloj bone priskribi 80% de tekstojn, por restajn 10% oni bezonus 20 regulojn, kaj por lastaj 10% de tekstoj oni bezonus tute alian teorion kaj por multaj homoj tiuj frazoj estus diskutindaj rilate al ilia korekteco. Tiu fenomeno estas konata sur la nomo principo de Pareto
Komputila lingvistiko en nuna Stato
Lingvistoj kaj programistoj multe lernis de fruaj malsukcesoj. La nunaj sciencaj laboraĵoj havas altan praktikan taŭgecon. Ekzistas sukcesaj projektoj, kiuj pritraktas nur unu limigitan kampon de lingvistiko. Aliaj projektoj povas uzi la rezulton de aliaj projektoj. Por tio pli grava estas ankaŭ la libera programado, kiu sen monaj komplikaĵoj permesas uzi fruajn rezultojn de aliaj projektoj. La GPL permesilo garantias, ke la laboro de homoj iĝas parto de homa heredaĵo kaj ne malaperas en iu tirkesto. Tiu laboro ne povas esti ankaŭ misuzata de komercaj firmaoj. Sed ĉiam ekzistas danĝero, ke grandaj komercaj fortoj, kiuj por iĝi pli granda uzas iliajn plej danĝeraj armilojn, tio estas advokatoj, por malpermesi al aliaj ian aktivadon kaj pensadon. La plej malnobla kaj malverplena ilo en monoj de advokatoj estas softvaraj patentoj.
Malkontentiga estas ankaŭ komercigo de universitataj projektoj. Kvankam multaj universitataj projektoj estas financitaj de publika mono, kiu devenas ja de niaj impostoj, la rezultoj de tiuj esploroj ne estas libere atingeblaj. Do por angla lingvo ekzistas la libera semantika mapo de vortoj WordNet, sed la simila projekto por eŭropaj lingvoj EuroNet estas atingebla nur je granda prezo. Multaj universitatoj kunlaboras en tiu kampo kaj interŝanĝas la rezultojn de iliaj esploroj senpage, sed tio ja signifus, ke nur universitatoj rajtas esplori science laŭ sciencaj principoj, laŭ kiuj ja la scienca kono estas publika bono. Fine tiu komercigita scienco helpus al neniu kaj rezultoj, kiuj ne estas atingeblaj en vero ne ekzistas.
Kompreno de aŭtoraj rajtoj ĉe lingvistikaj fontoj povus esti malfacila problemo por komputila lingvistiko. Ĝenerale lingvo ne apartenas al iu speciala ulo. Zamenhofo ankaŭ igis Esperanton publika bono kaj li rezignis pri aŭtoraj rajtoj de Esperanto. Sed tio ne estas certa afero ĉe vortaroj. Vortaro estas unue la propraĵo de eldonejo. Ĉu vorto, kiu aperas en vortaro iĝas aŭtomate propraĵo de eldonejo. Ĉu iu frazo, aŭ iu speciala uzo de vorto estas propraĵo de aŭtoro de tiu frazo. Por eviti tiujn problemojn mi nur uzas liberajn fontojn kiel REVO ĉe mia programado. Povus esti, ke aliaj fontoj estas pli bonaj, sed uzo de tiuj fontoj estas malrekomendinda. Ni pripensu do la situacion. Mi korektis la internan vortaron en programo laŭ priskribo de profesia vortaro en tradicia libra formo, kiun mi aĉetis je normala prezo. Ĉe unu vorto tio ja ne estas problemo, sed se mi tion faris ĉe 100 aŭ 1000 vortoj, mi povas havi problemojn, ĉar iu povas akuzi min, ke mi ŝtelis la parton de vortaro. Tiu povos esti tre granda problemo ĉe Esperanto, ĉar tiu lingvo estas nova kaj konstruita, kontraŭe al naciaj lingvoj oni povus trovi la kreinto de iu vorto, frazo kaj speciala gramatika uzo. Mi esperas, ke mi ne havos tiun problemon, ĉar nek la programo nek Esperanto iĝos tiel popularaj, ke iuj komercistoj havos interesojn financi advokatojn por malkonstrui tiun projekton. Eble pro normalaj uloj tio ĝenerale ŝajnas tre malebla afero, sed tio bedaŭrinde ofte okazas ĉe programado.
Ekestis tamen pozitivaj aferoj. Multaj komercaj firmaoj publikigas la rezultojn de ilia laboro laŭ GPL permesilo. Ekzemple tre konata programlingvo JAVA iĝis lastatempe la parto de libera programaro. Memkompreneble, la firmaoj faras tion en situacio, kiam ili ne povas venki la komercan konkuranton kaj per tiu paŝo, ili volas minimume malfortigi la konkuranton. Sed firmaoj ankaŭ rimarkis, ke malfermo de projektoj pozitive influas la projektojn kaj tamen lasas al ili la eblojn perlabori monon per aldonaj servoj. Ankaŭ granda lingvistika projekto Open Logos iĝis malferma. Tio estas tre kontentiga afero, ĉar fontoj, kiuj unue iĝas parto de libera programado ne povas esti enproprigitaj de iu, do ili fariĝas la parto de homeca heredo.
Nun ekzistas multaj fontoj en interreto, de kiu oni povas elĉerpi la scion pri lingvistiko. Okulfrape estas, ke precipe nur pro angla lingvo ekzistas kompleta oferto de solvoj. Malfeliĉe angla lingvo estas la lingvo, kiu apartenas de komputila vidpunkto al la plej malfacila lingvo por komputila pritraktado. Tial la progreso estas tre malrapida. Tre kontentiga por mi estas la fakto, ke ankaŭ por pola kaj germana lingvo aperas bonaj fontoj. (pola gramatiko, Germana vortaro de sinonimoj) Ili estas ofte publikigaj de hobiuloj, sed kun bona kvalito.
Por grandaj lingvoj oni nun povus konstrui fortan sistemon de partoj, kiuj nun ekzistas. Programistoj scias, ke intergluo de moduloj, kiuj uzas diferencajn komputilajn teknikojn estas ofte tre malfacila tasko. Tial oni ne atendu rapidan progreson.
En komerca kampo ekzistas firmaoj, kiuj sukcesas vendi lingvistajn programojn al profesiaj tradukistoj je granda prezo. Kvankam profesiaj tradukistoj estas ofte plej grandaj kritikistoj de ideo de maŝina tradukado, ili mem ofte uzas tiujn programojn. Mi miras, ke ĝis nun oni pagas por tradukoj je tradukita vorto, kvankam ofte por kutimaj dokumentoj, la tradukistoj havas ja ŝablonojn kun preta tradukado sur iliaj komputiloj kaj ĉe „tradukado“ ili devas enskribi nur kelkajn nomojn kaj datojn. La profesia tradukado de oficialaj dokumentoj estas fabriko de mono, kaj tiuj homoj faros ĉion por longe havi tiun fonton de facila mono.
Oni ne esperu, ke profesiaj programoj aperas iam por Esperanto. Ne ekzistas oficialaj dokumentoj en Esperanto, kiujn oni devus traduki, do la neceso de tiuj programoj preskaŭ ne ekzistas. Nun nur kelkaj grandaj lingvoj estas entute pritraktataj de tiuj programoj.
Esperanto en komputila lingvistiko
Oni ofte parolas en Esperantujo pri taŭgeco de Esperanto por lingvistika komputiko. Tamen la rezultoj estas mizeraj. La principa kaŭzo de tio estas, ke projektoj, kiuj estas pagitaj de naciaj fontoj, ne volas subteni ne nacian lingvon. Esperanto povis ja ŝteliri en tiujn projektojn kiel interlingvo, sed verdire Esperanto ne estas el teknika vidpunkto bona interlingvo (legu). Mi ne pensas, ke tio ofte reokazos en la venonta tempo. Sed ekzistas projektoj en alia direkto, kiuj estas subtenataj de esperantista medio. Por mi la gravaj projektoj estas REVO, Tekstaro kaj PMEG. Esperanta vikipedio estas ankaŭ grava. Oni devas konstati, ke Esperanto konkurencas kun aliaj lingvoj en tiu kampo. Se oni komencas lingvistikan projekton, oni pritraktas, kiuj fontoj kaj solvoj estas nun uzeblaj kaj pretaj. En la unua flanko Esperanto promesas esti pli facila, en la dua flanko aliaj lingvoj (principe angla lingvo) havas pli da pretaj solvoj kaj fontoj. Mi pensas, ke ankaŭ en tiu kampo Esperanto jam malvenkis kun angla lingvo. Unue nun ĉiu programisto konas jam anglan lingvon, ĉar sen angla lingvo si ne sukcesis iĝi programisto. Due, kiu volas lerni novan kaj malofte uzatan lingvon de malgranda grupo por eksperimenti kun ĝi? Oni faras tion nur pro hobia intereso aŭ por lernado. La facileco de Esperanto ne povas konkeri la vastan aperon de angla lingvo en komputila lingvistiko. Mi pensas, ke nun la unua ŝanco per ia estado de Esperanto en komputila lingvistiko estas hobiaj projektoj kaj libera programado. En tiu situacio estas grave, ke ĉiuj fontoj estas publikigitaj laŭ libera permesilo.
Libera programado kaj komputila lingvistiko
Libera programado havis kelkajn sukcesojn en sia historio. La plej granda sukceso estas la libera mastruma sistemo linukso. Nun estas eble uzi komputilon, kiu rulas nur liberajn programojn. Tiuj programoj estas eĉ tiel grande sukcesaj, ke komercaj firmaoj, interesiĝas pri tiuj projektoj, kaj ne programistoj uzas tiujn programojn. Ĝis nun liberaj programoj estas skribitaj plejofte de programistoj por programistoj. Ili programis mastrumajn sistemojn, redaktilojn, programajn ilojn por sia ĉiutaga laboro. La natura lingvo estas por programistoj ne tre interesa. Tamen restas iama revo de fruaj programistoj programi komputilon, kiu pensas kaj kiu tradukas.
La defio de maŝina tradukado estas do interesa kaj konata por programistoj. Ĝis nun aperis jam kelkaj projektoj, kiuj aŭ rapide mortis aŭ ne estas aktive pluevoluigita (Traduki, Linguaphile, Translato). Tio estas normala afero. Plej ofte programistoj ne estas pretaj sole kaj por longa tempo prilabori unu temon. Ĉar ekestas tre multa kvanto de liberaj projektoj, oni nur tre malfacile povas trovi uzantojn kaj helpantojn. Ŝanco, ke iu projekto travivos la tempon de intereso de la unua aŭtoro estas tre malgranda. Komputilaj projektoj bezonas kutime kelkajn jarojn de maturiĝo. Tiu longa tempo estas necesa ĵus por lingvistikaj projektoj, ĉar en tiu tempo oni devas lerni vastan teorion. La maturiĝoestas ankaŭ necesa post reagoj de uzantoj. Estas tre malfacila afero programi programon, kiu estas facile uzebla. Por programistoj, iliaj propraj programoj estas ĉiam facilaj, tial ili nur malfacile rimarkas malfacilaĵojn pri uzebleco de programoj.
Projekto „Esperantilo“
Kiam mi komencis programi la unuajn liniojn de kodo por Esperantilo, mi neniam pensis, ke post du jaroj mi programos maŝinan tradukadon kaj pensos pri sintaksa analizo. Mi volis nur havi simplan redaktilon por vindozo kaj linukso, per kiu sen peniga instalado oni povas skribi tiujn strangajn esperantajn literojn. Poste mi pensis pri literumado kaj gramatika korektado, ĉar mi ĉiam forgesis la akuzativon. Mi skribis la programon unue por mi mem. Poste mi legis multe pri maŝina tradukado kaj ĝenerale pri komputila lingvistiko. Mi rimarkis, ke aŭtoroj ne estis bonaj programistoj, kaj ke ili tute ne konas novajn teknikojn de programado. En tiama tempo mi okupiĝis pri nova programa lingvo XOTcl kaj programada medio XOTclIDE, kiun mi antaŭe mem programis. Mi serĉis temon por pruvi la taŭgecon de tiu lingvo kaj programa medio. En miaj fruaj spertoj mi rimarkis, ke tiu programa lingvo permesas al mi pli efikan programadon. Mi ankaŭ trovis en interreto kelkajn materialojn pri Esperanto. Esperanton mi lernis frue tute hazarde de mia kolego kaj mi eĉ partoprenis la lokan kurson en urbo Essen. Mi ne iĝis membro de iu esperanta asocio. Mi trovis tre viglan REVO, MPEG kaj Tekstaron. Do mi ne devis komenci de nulo. Mi havis fontojn, kiujn mi povis uzi. Mi ankaŭ informis min pri similaj projektoj kaj ofte traserĉis la reton. Mi ne havas grandajn celojn kaj planojn, sed mi provis aldoni novajn funkciojn, kaj se ili funkcias, mi programas plu. Ĉar mi sciis, ke la risko, ke mi ne sukcesos, estas tre granda, mi de komenco elektis kelkajn strategiojn por malaltigi tiun riskon.
Mia programa metodo estas grande influata de tiel nomata Extrame Programming, kiun mi konis de programlingvo Smalltalk. La programa medio ebligas tiel nomatan interaktivan programadon. Laŭ tiu metodo oni povas ŝanĝi programon, kiu samtempe rulas. Tio estas tre helpema ĉe lingvistikaj programoj kaj tio instigas al eksperimentoj. Unue mi limigis la plej forajn celojn al tiuj, kiuj mi mem povas iam atingi. Do mi volis elpensi novan lingvon aŭ konstrui tute novan teknikon. Due mi difinis por mi kelkajn strategiojn:
- La programo celas nur traduki de Esperanto kaj prilabori nur Esperantan lingvon.
- La celaj lingvoj estas lingvoj, kiujn mi mem konas.
- Mi ne kalkulas je helpo de aliaj je moto: „mi komencis ion kaj la aliaj tion finigis“.
- Mi uzas jam konatajn teknikojn kaj teoriojn. Ĉar mi ne estas lingvisto mi ne volas eklabori novan sciencajn teoriojn.
- Se tio estas ebla, mi uzas pretajn liberajn solvojn. Mi koncentriĝis pri specialaj esperantaj temoj, ĉar estas ne verŝajne, ke aliaj tiun faris.
- La programo ĉiam devus esti uzebla por iu takso kaj liveri rezultojn. Poste la celo estas plibonigi la rezultojn. Mi celas evoluan progreson. Mi ne volis, ke la programo estas uzebla nur post kelkaj jaroj.
- Mi publikiĝas samtempe ĉiujn rezultojn: vortarojn, fontan kodon, testajn frazojn.
- Mi unue faras taskojn, kiujn nur mi mem povas fari. Do mi programas, sed mi uzas pretajn vortarojn. Mi mem ne kompletiĝas la vortarojn, ĉar tio povas fari poste aliaj. Mi plibonigas la vortarojn nur ĉe evidentaj eraroj.
- Mi serĉas la dialogon kun uzantoj laŭ la maniero de libera programado.
- Mi ne kunligas kun la programo iujn komercajn planojn kaj mi evitas ligojn kun komercaj medioj.
Esperantilo estas eksperimento, la programado povus ĉiam finiĝi, ekzemple ĉar mi ne vidus ŝancojn por plua evoluo aŭ mi ne plu ĝojus la programadon. Tial mi volas sekurigi la rezultojn de tiu projekto. Mi publikigas ĉiujn fontojn kaj vortarojn. Sekvaj projektoj povus tiujn fontojn uzi. Mi ankaŭ skribas tiun blogon por dokumenti la laboron. Ankaŭ, se la projekto estas hobia kaj malperfekta, ĝi povas esti fonto por kritiko kaj por komparo kun sekvaj projektoj.
Homoj sugestis al mi, ke tiu projekto estas tro ambicia, por hobia projekto de unu homo. Jes, mi certe tute same pritraktis tiun projekton frue, se iu donis al mi la planon programi ĝin. Sed nun mi jam pruvis por mi mem, ke estas eble pli ol mi tion pensis frue. Certe tio ne estas pruvo, ke la projekto progresas en simila tempo poste. En tiu projekto oni do ne pritaksu planojn sed faktojn. Kaj faktoj ne povas esti ambiciaj, ili estas veraj aŭ malveraj. Mi skribas tion, ĉar mi spertas, ke ofte eĉ uzantoj, kiuj iomete uzis la programon, ne raportas erarojn, ĉar ili pensas, ke la projekto ne havas ŝancon de pluevoluo.
Mi ankaŭ ne estas naiva programisto pri libera programado, ĉar mi havas longan sperton en tiu medio. Fakto estas, ke plej granda parto de projektoj vivas de unu persono, do mi devas fari ĉion sole. Programistoj, kiuj ĵus skribis kelkajn liniojn kaj poste varbas por aliaj programistojn devas seniluziigi, se ili esperas je granda helpo. La motivoj de programistoj de libera programado estas diferencaj, pura helpemo estas tre malofta. Oni certe ne povas kalkuli je helpemo de profesiuloj, ĉar ili vivtenas sin per ilia profesieco. Ankaŭ oni ne kalkulu je preciza kritiko, tio ankaŭ estus ja ia helpo.
En tiu tempo mi ankaŭ lernis multon kaj devis adapti miajn fruajn atendojn. Unue mi devis konstati, ke Esperanto estas natura lingvo kaj ne tre diferenca de aliaj naturaj lingvoj. Ekzistas kampoj en Esperanto, kiuj estas same komplikaj kiel en aliaj lingvoj. Do la facileco de Esperanto estas nur limigita en ceteraj kampoj.
Due mi rimarkis, ke la teorio de Esperanto ne estas fiksa. Ekzistas multaj diferencaj teorioj pri tiu lingvo kaj estas malfacile trovi klarajn respondojn pri detaloj. Ankaŭ la fontoj, kiuj estas atingeblaj en TTT, ne estas kompletaj.
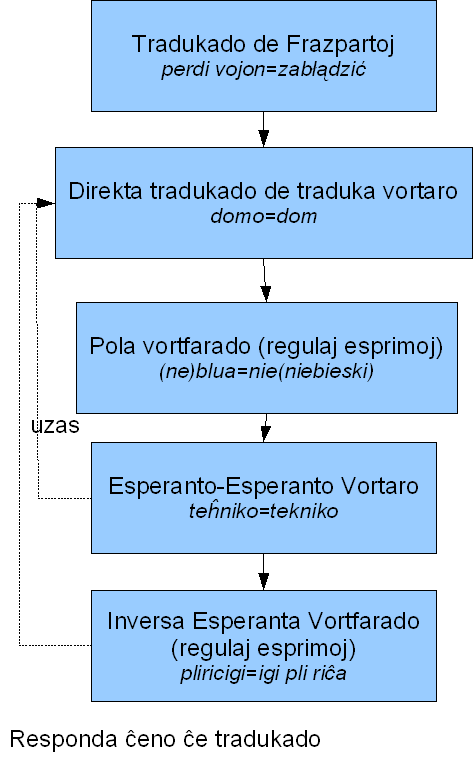
Mi devis do ofte prilabori bazajn fontojn kiel vortaroj. Ĉar Esperanto estas tre nova lingvo kaj forte evoluas, ne ekzistas fiksa maniero de ĝia uzo. Esperantistoj ofte imitas sian gepatran lingvon. Tial la sintaksa analizo estas granda defio. La tre efika vortfarado en Esperanto malfaciligas samgrade la maŝinan tradukadon. Multaj statistikaj teknikoj de maŝina tradukado ne aplikebla por Esperanto, ĉar en tiu lingvo mankas sufiĉe grandaj paralelaj tekstoj (Tekstoj en du aŭ pluraj lingvoj). Sed tio estas ja normala prezo de naiva kaj hobia komenco.
La reagoj de uzantoj kaŭzas ofte pli da labore ol helpo. Sed ili estas necesaj kaj mi ĉiam respondas je leteroj de uzantoj kaj interesantoj. Mi ĝojas ĉiam pri la reagoj kaj mi povas diri, ke ĉiu, kiu skribas al mi, partoprenas en la projekto. Tiu blogo estas ankaŭ por mi la ilo por malplialtigi la laboron kun reagoj de uzantoj. Mi povos ja nun ofte respondi: Bonvolu legi la blogon kun numero tiu kaj tiu. Mia espero estas ankaŭ, ke aliaj programistoj malkaŝas por si mem, ke komputila lingvistiko ne estas tial senespere komplika kampo, kiel oni tion edukas.