La nombro de programaj lingvoj estas tre granda (pli ol 1000), kaj ĉiun jaron novaj programaj lingvoj ekestas. Oni povas diri pri evoluo de programaj lingvoj, ĉar la ideoj kaj konceptoj de programado estas heredigitaj de unu lingvo al alia. La evoluo ofte progresas en multajn diferencajn direktojn, sed kelkaj lingvoj denove unuigas konceptojn de aliaj maljunaj lingvoj. Do ankaŭ en la kampo de programaj lingvoj ni havas la babilan turon. (Wikipedia: history of programming languages)
La unuopaj programaj lingvoj mem evoluas kaj estas ofte plivastigataj kaj influataj de evoluo de aliaj lingvoj. Programistoj tre vigle kaj volonte diskutas pri la perfekta kaj la plej utila programa lingvo.
La kaŭzoj por diferenceco de programaj lingvoj estas diferencaj ol tiuj de naturaj lingvoj. La novaj programaj lingvoj ekestas pro teknika aŭ scienca evoluo aŭ komercaj interesoj de firmaoj. Ĉiu nova programlingvo promesas pli bonan uzadon de tekniko, pli grandan efikecon, pli grandan uzeblecon aŭ taŭgecon por iu tasko, kaj pli vastan subtenon de diferencaj komputilaj sistemoj. Multaj malgrandaj sciencaj programlingvoj ekestas kiel eksperimento aŭ nur pro kreemo de sciencistoj.
Mi mem lernis ĝis nun pli ol 20 programajn lingvojn kaj uzis pli longan tempon ĉirkaŭ 12 lingvojn. Miaj plej gravaj programaj lingvoj ordigitaj laŭ tempo de lerno estis:
- Basic – C-64
- Assembler – C-64
- C – Amiga 500
- C++ – Amiga 500
- Modula 2 – (dum studado)
- Java
- Tcl
- Perl
- XOTcl
- Smalltalk
- C#
- JavaScript
Mi pristudis ankaŭ: Ruby, PHP, Python, Haskell, Lisp, Polog, Oz (verŝajne ankaŭ kelkaj aliaj). Aktuale mi programas plej intense en lingvoj: Java, XOTcl, C#.
La plej popularaj programaj lingvoj estas lingvoj kun plej multnombra programaro kaj plej granda nombro de programistoj. Aktuale tiuj lingvoj estas: C, Java, C#, Perl, Python, Visual Basic, PHP, JavaScript, Ruby kaj maljuna Cobol. Vidu ankaŭ Statistiko pri populareco de programlingvoj Tiuj indeksoj kutime pritraktas kelkajn indicojn por komputi la popularecon. Lingvo, kiu iĝis plej rapide populara, estis en la jaro 2006 la lingvo Ruby. Programistoj do lernas tiujn lingvojn por pli facile trovi la laboron. Oni povas trovi pli da informoj pri tiu lingvo.
Oni povas diferenci kelkajn kategoriojn kaj trajtojn de programaj lingvoj.
- kutima arto de problemoj, kiujn pritraktas la lingvo
- baza koncepto de lingvo: funkcioj, objektoj, …
- testado de sintakso (tipoj)
- arto de kurado
- baza permesilo de lingvo
- lingvoj por cetera mastruma sistemo.
- komunikebloj kun aliaj programoj aŭ sistemoj
- reuzado de alilingvaj programoj
- lingvoj por cetera homgrupo: lernantoj, matematiksitoj, hobiuloj
Programistoj scias, ke principe per ĉiu lingvo kun potenco de Turing-maŝino estas eble programi ĉiujn algoritmojn. Mia sperto estas, ke oni uzu por ĉiu takso la plej avantaĝan lingvon. Estas bone koni kelkajn programajn lingvojn kaj ne preferi ĝenerale unu ceteran lingvon. Ofte oni povas reuzi spertojn de programistoj en unu lingvo por programi sistemon en la alia lingvo. Oni devas pripensi ne nur la nunan situacion, sed ankaŭ aliaj ĉirkunstancojn.
- Kiuj aliaj programistoj devas flegi la programon
- Kun kiuj aliaj sistemoj devas komuniki la programo
En profesia laboro la elekto de programa lingvo ne estas tasko de programisto kaj ofte tio estas historia elekto.
Lernado de nova programa lingvo estas peniga laboro, sed kun ĉiu aldona lingvo, kiun oni regas, la lernado estas pli facila. Programistojn ofte bezonas kelkajn jarojn por bone regi iun programan lingvon. Grava estas ankaŭ la regado de programaj iloj kaj de programa medio. Oni bezonas ankaŭ spertojn pri kutimaj solvoj kaj insidojn de tiu programa lingvo. Tial programistoj forte kontraŭas la aliajn lingvojn ofte nur por tute egocentraj kialoj, kiuj estas la sekurigo la valoro de ilia sperto
Elekto de programlingvo
Mi pensas, ke plej ofte tiu elekto estas tute hazarda kaj dependas de lernejo kaj laborejo de programisto. Se oni havas la ŝancon mem elekti la lingvon oni pritaksu:
- Popularecon de lingvo (aktuala kaj historia)
- Nombro de libroj pri tiu lingvo
- Nombro de uzantoj. Vigleco de komunumo de programistoj
- Historio kaj deveno de programa lingvo
- Ekzisto de programa medio kaj aldonaj programaj iloj por tiu lingvo
- Nombro de ekzemplaj programoj en tiu lingvo
- Kategorio de programoj programitaj en tiu lingvo
- Aldonaj ebloj de lingvo (GUI, Ligiloj kun dato-bazo, XML)
- Permesilo kaj komerca aŭ libera uzado de baza fonto de programa lingvo
Programa Lingvo por Komputila Lingvistiko
Lingvistika programado estas tre vasta kampo, kaj ne estas facile diri, kiu programa lingvo estas la plej avantaĝa por tio. Oni devas diferenci inter sciencaj esploraj programoj aŭ sistemoj programitaj por averaĝa uzanto. Ofte lingvistika programaro estas parto de aliaj grandaj sistemoj (ekzemple: tekstaj redaktiloj) kaj devas subordigi sin al ruloj de gasta sistemo.
Por lingvistika programaro grava estas facila reuzado. Tial multaj lingvistikaj sistemoj estas programitaj en Javo, kiu nuntempe havas grandan rolon en komerca programado. La ĉefa avantaĝo de tiu programlingvo estas granda populareco en pluraj kampoj. Sed ankaŭ ekzistas grandaj lingvistikaj programoj programitaj per skriptaj lingvoj kiel: Python (NLTK), Perl kaj Tcl (Ellogon).
Mi spertis, ke sekvaj trajtoj estas gravaj por komputila lingvistika:
- subteno de UTF-8 kaj aliaj historiaj enkodoj
- programado de grafika uzantointerfaco
- facila kaj utila prilaboro de signoĉenoj
- por prilaboro de tekstoj estas tre praktikaj regulaj esprimoj
- prilaboro de XML-dokumentoj
- interfaco al SQL-datumbazoj
- bona interkomuniko kun aliaj programoj
- bona programa medio
- facila instalado kaj pretigo de instaladaj paketoj
Kelkajn lingvistikaj sistemoj, kiuj bazas sur limiglogika programado aŭ predikatkalkulo, uzas specialajn programlingvojn kiel Prolog aŭ Oz. Tiuj sistemoj estis plejofte kreitaj en universitataj medioj.Mi mem spertis, ke la plej avantaĝaj estas dinamikaj skriptlingvoj, kiuj estas ankaŭ nuntempe taŭgaj por grandaj sistemoj. Nun la plej popularaj kaj rekomendindaj estas lingvoj: Python kaj Ruby. Frue la programistoj ofte diskutis pri esprimpovo de lingvo aŭ sintakso. Mi ŝatas lingvoj, en kiuj oni povas per mallongaj esperimoj programi potencajn reuzeblajn strukturojn. Tiuj lingvoj estas: Smalltalk, Ruby, Python aŭ XOTcl.
Jen ekzempla kodo, kiu donas la lastaj 2 literon de vorto por diferencaj programaj lingvoj.
- Java –
vorto.substring(vorto.length()-2)
- C# –
vorto.Substring(vorto.Length-2)
- Python –
vorto[-2:]
- Tcl –
string range $vorto end-2 end
- Smalltalk –
vorto last: 2
- Ruby –
vorto[-2,2]
- C –
if (strlen(vorto)>2) vorto += strlen(vorto)-2;
- C++ –
new String(vorto,vorto.lenght()-2,2)
Por C kaj C++ tiu takso estas eĉ pli komplika, ĉar oni devas ankaŭ pripensi la uzadon de memoro. Oni bone vidas, ke tiu simpla tasko estas en Smalltalk kaj en skriptaj lingvo la plej klara kaj mallonga.Lingvoj kiel C++, Java aŭ C#, kiuj havas ridigan statikan tipan sistemon havas tre grandan rolon en komerco kaj estas uzataj por tre grandaj komercaj projektoj. Sed por komputila lingvistiko, kie la algoritmoj povas esti tre komplika, tiu ridiga tipa sistemo povas tre ĝeni kaj malutili. Tiuj lingvoj ne oferas potencajn abstraktaĵojn por mallongigi la programan kodon. Do la programado per tiuj lingvoj estas malpli efika kaj la rezulta kodo pli longa. Tio estas ankaŭ maloportuna por posta flego de sistemo.
La konata strategio estas ankaŭ programi unue la prototipon en skripta lingvo kaj poste, kiam oni estas certa pri la funkciado, reprogrami tiun modulon en lingvo kiel C,C++, Java aŭ C#. Tion oni faras plej ofte por rapidigi aŭ malpligrandigi tiun modulon. Lingvo Tcl estas ankaŭ nomata kiel glutea lingvo. Tiu lingvo estas do uzata kiel gluteo de moduloj programitaj en lingvo C aŭ C++. Ankaŭ aliaj skriptaj lingvoj povas esti uzataj kiel gluteo.
Mia sperto estas, ke ankaŭ grava estas stabila programa medio, populareco kaj aldonaj moduloj. Ĉiam estas pli oportune reuzi fremdan modulon ol programi ilin de komenco. Oni atentu ankaŭ, ke aliaj programistoj volas ankaŭ tralegi kaj reuzi la programpecojn. En profesiaj sistemoj ĉiu linio de kodo estas nur unufoje skribita sed averaĝe 10-foje tralegita. Fine al neniu malutilas lerni multajn programajn lingvojn.
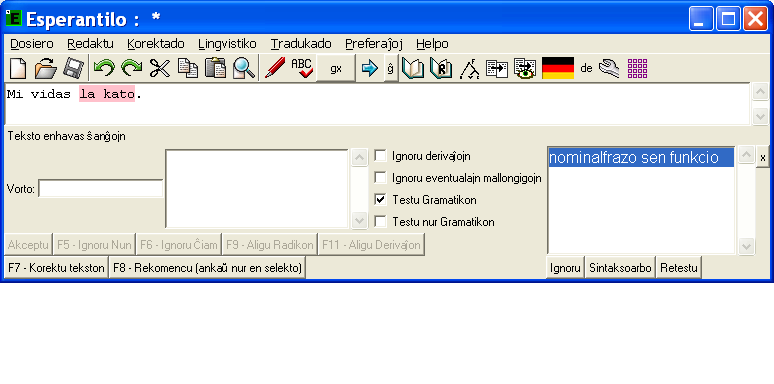
Programa lingvo de „Esperantilo“
Esperantilo estas programita en Tcl (Wikipedia) kun aldona objektema modulo XOTcl. La lingvo apartenas al tiel nomataj skriptaj kaj interpretaj lingvoj. Tiu lingvo estas ofte uzata de ne informatikistoj, ĉar ĝi estas facile lernebla. Lingvo Tcl estis tre populara en 80-aj jaroj, sed ĝia populareco nun konstante malkreskas. En lasta tempo Tcl malgajnas la popularecon principe por lingvoj: Python kaj Ruby, kiuj oferas enprogramitan objektemon.
Normale oni programas en tiu lingvo nur malgrandajn programojn. Esperantilo estas en tiu kazo escepto. Tio estis ebla plejparte, ĉar mi uzis objekteman metodon por strukturi la programon. Kiel programada medio mi uzas XOTclIDE. Tiu medio estas programita laŭ modelo de Smalltalk medioj. Ĝi ebligas interaktivan metodon de programado kaj facilan trarigardon de sistemo.
Mi mem elektis tiun lingvon pro mia propra prefero. Mi spertis, ke per skriptaj kaj dinamikaj programaj lingvoj mia efikeco de programado estas la plej alta. Kompare al programlingvo Java aŭ C# per XOTcl mi estas 5-10 foje pli efika, kvankam mi ankaŭ havas multjaran sperton kun tiuj lingvoj. Tcl havas grandan maturan komunumon de programistoj. Ilia ĉefa medio estas Wiki Tcl kaj mesaĝlistoj comp.lang.tcl. Ekzistas multaj libroj kaj ekzemplaj programoj por tiu lingvo.
La efikeco de programado kaj eblo de rapidaj eksperimentoj estis la plej grava kaŭzo por elekto de lingvo. Sed ankaŭ aliaj trajtoj de tiu lingvo estas oportunaj por lingvistika programado:
- subteno de UTF-8
- facileco de programado de grafikaj uzantinterfacoj
- subteno de ĉiuj aktualaj mastrumaj sistemoj
- malgranda dimensio de instaladaj programoj
- direkta subteno de signoĉenoj kiel ĉefa koncepto de lingvo
- tre malgranda nombro de sintaksaj reguloj
- facila lernado
- facila reuzo de aliaj programoj per C-lingvo interfaco
- facila enmikso de C/C++-moduloj
- facila instalado por averaĝa uzanto
Ĉar neniu lingvo estas perfekta. Mi rimarkas ankaŭ kelkajn maloportunaj trajtojn:
- Lingvo ne subtenas la koncepton de logika programado aŭ regulbazita programado, kiu estas ofte uzataj ĉe sintaksa analizo
- La lingvo ne atingas la plej bonan rapidecon de C-programoj.
- Objektema programdo per aldona modulo XOTcl ne estas tre populara
- Malgranda komerca uzado de tiu lingvo (escepte de administrado de komputilaj sistemoj). Preskaŭ neniu subteno de grandaj komputilaj firmaoj.
- Malgranda akcepto de tiu lingvo de aliaj programistoj