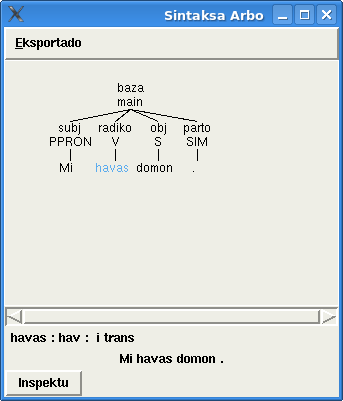
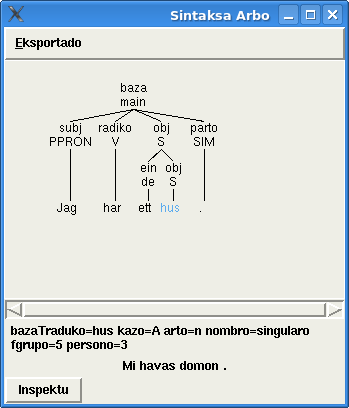
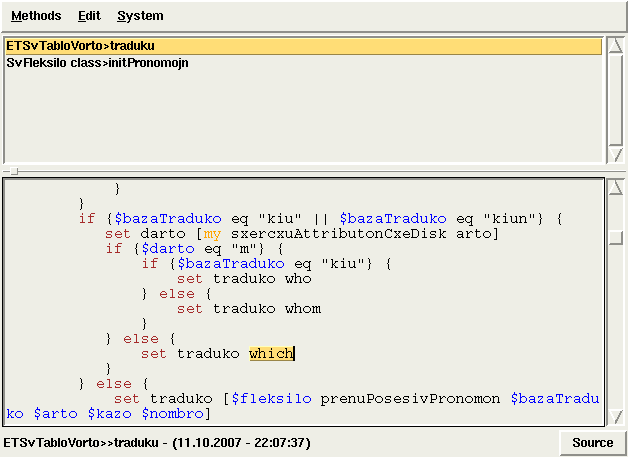
Esperantilo enhavas funkcion de traduka memoro kaj ankaŭ la specialan redaktilon por tradukado de teksto laŭ segmentoj (frazoj).
Esperantilo regas formatojn TMX kaj XLIFF. Ĝi povas legi formatojn HTML, XML kaj OpenOffice.
Ŝajnas tamen, ke preskaŭ neniu uzas tiujn funkciojn. Unue tiuj funkcioj estas por averaĝa uzanto tro progresinta, ke li ne bezonas ilin. Due la programo eble estas tro ŝarĝita per funkcioj, ke uzantoj estas malcertaj, por kio tiu programo taŭgas.
Eble kelkaj homoj pruvis tiun funkciojn, trovis erarojn kaj lasis tion. Mi nenion eksciis pri tio. Nun havis antaŭ kelka tempo kontakton kun uzanto de OmegaT. Tiu programo estas plej konata traduka programo en modo de libera programado. Esperantilo estas ankaŭ listigita en la listo de programoj, kiuj oferas tradukan memoron. Mi ne varbis por tiuj funkcioj kaj tiuj funkcioj ne estas tre fidindaj kaj ne vere finprogramitaj. En la dua flako tiuj funkcioj estas ankaŭ interesaj por Neesperantistoj. Tial oni povus varbi per tiuj funkcioj por esperanta lingvo. Almenaŭ kelkaj homoj, kiuj uzas tradukan memoron, ekscius pri tiu lingvo.
Lastajn semajnojn mi laboris pri plibonigo de tiuj funkcioj. Mi trovis kaj korektis multajn erarojn. Mi ŝanĝis ankaŭ la metodon de konservado de traduka memoro kaj vortaroj. Nun mi uzas sqlite datumbazon. Tio tre rapidigis la laboron de programo. La maŝina tradukado iĝis eĉ 6 foje pli rapida.
Tradukado de programoj
Esperanto enhavas potencan tradukan memoron kaj povas iel maŝine traduki de angla lingvo al esperanta lingvo. Do la programo povus esti interesa por tradukado de programaro. Mi rigardis kelkajn liberajn projektojn pri tradukado de programaro. Temas pri tradukado de angla lingvo al Esperanto.
Sekvaj projektoj estas plej grandaj kaj plej progresintaj:
Helpe de Translate toolkit mi kolektis ĉiujn tradukojn en unu grandega datumaro.
Mi aliformis la diferencajn formatojn por tradukado al XLIFF-formato. Poste mi importis ĉiujn XLIFF-dosieron al traduka memoro de Esperantilo. Tio daŭris kelkajn horojn.
Ne estis ankaŭ faĉile trovi ĉiujn fontojn de tradukadoj en la reto.
Fine mi havas 24MB grandan tradukan memoron kun 58.000 tradukitaj frazoj.
Estas interese, ke antaŭ 20 jaroj nur kelkaj registaroj de plej riĉaj landoj havis sufiĉe grandan komputilon por prilabori tiun amason da datumoj.
Tio estas bona fonto por sekvaj laboroj. Oni povas uzi tiun tekstaron tre diference.
Ĝi povus helpi ĉe traduko de aliaj programoj. Mi pensas ankaŭ pri aŭtomata kredo de vortaroj de tiu datumaro. Mi jam eksperimentis pri tio kun pola lingvo.
Antaŭ 4 jaroj, kiam mi komencis okupi pri komputila lingvistiko kaj Esperanto, tiu datumaro ne estis ebla. Estas tre ĝoige, ke Esperanto evoluas en libera programado. Tiu nuna bazo povus eĉ plirapidigi la disvastigon de Esperanto en tiu kampo.
Enkoduko – Kiel uzi Esperantilo por i18n
Unue instalu la plej novan eldonon de Esperantilo. Mi preskaŭ ĉiumonate pretigas novan plibonigitan eldonon.
Due ŝarĝu tm_en_eo.tmsql.gz la tradukan memoron por tradukado de angla al esperanta lingvo. Depaku tiun dosieron kaj kopiu ĝin al loko ~/Esperantilo aŭ sur Vindozo al dosierujo Esperantilo en dosierujo de uzanto (en angla eldono C:/Documents and Settings/uzanto/).
Lanĉu Esperantilon. Unue vi povas trarigardi la tradukan memoron. Tial vi ankaŭ provos, ke la importado de traduka memoro sukcesis. Agordu la fontan lingvon kiel angla lingvo kaj cela lingvo kiel Esperanto. Vi povas uzi por tiu menuon „Preferaĵoj->fonta lingvo“ kaj „Preferaĵoj->cela lingvo“ aŭ uzi la flagajn butonojn.
Lanĉu la redaktilon de traduka memoro per menuo: „tradukado->Traduka Memoro->redaktilo de traduka memoro“.

Nun vi povas prepari la tradukadon de via ŝatata programo de angla lingvo al esperanta lingvo. Vi unue bezonas la fontan dosieron en formato XLIFF. Vi povas uzi la programon po2xliff de projekto Translate toolkit por transformi kutiman po-dosieron al xliff-dosiero.
Nun vi povas lanĉi la tradukan asitanton de Esperantilo.
Uzu por tio la menuon „Tradukado->Tradukado asistanto“.
Vi povus ankaŭ lanĉi la redaktilon de xliff direkto de konsolo
./esperantilo.bin -segmentilo ./esperantilo.bin viadosiero.xliff
Vi elektu la fontan lingvon kiel angla lingvo (en) kaj celan lingvon kiel Esperanto (eo). Poste vi povas traduki la projekton per tn. traduka segmentilo.
Vi tradukas po unu elemento (segmento).
Kutime la programo pruvas traduki la frazon maŝine. Se ekzistas la traduko en traduka memoro, vi povas akcepti tiun tradukon.
Oni povas ankaŭ traduki la tutan dosieron aŭtomate per funkcio „Traduku al fino plenu aŭtomate“ aŭ traserĉi la tekston laŭ traduka memoro per funkcio „Prenu tradukojn de traduka memoro“.
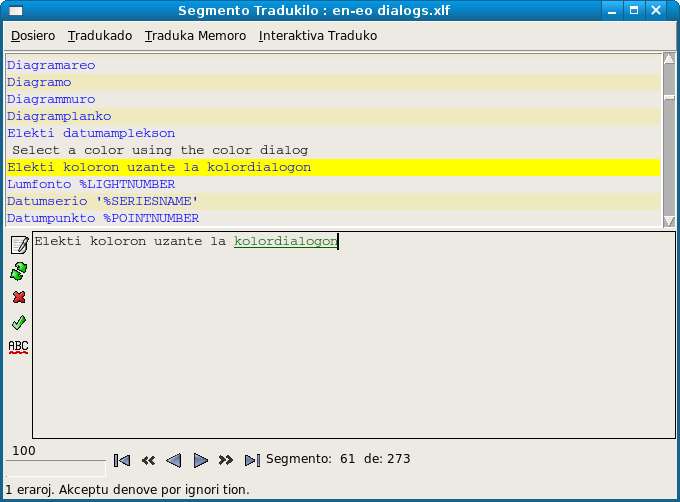
Trarigardo de tradukado
Nun mi kolekti pli ol 50000 tradukoj kaj havis okazon iom trarigardi tiujn tradukojn.
Mi unue serĉis la tradukon de „close window“ kaj trovis:
- Fermu fenestron
- Malfermu fenestron
Interesa eraro. Mi ankaŭ ĝin iam faris. Kaj poste nur „Close“ mi trovis
- Fermi
- Fermu
Mi mem preferas la ordonan formon, ĉe ja temas pri komando do ordono. Kutime oni tradukas en naciaj lingvoj tiujn komandojn kiel ordonoj. En germana lingvo oni uzas infinitivon („Schliessen“). Sed en germana lingvo oni ĝenerale ofte uzas tiun formon kiel ordono (senpersona ordono) „Arbeiten! Arbeiten!“, eble ankaŭ mallongigo de „Arbeiten Sie!“. Ankaŭ la angla lingvo uzas ordonon, la infinitivo estus „To close“.
Mi ŝatas la formon „u“, kiu ne nur estas ordono, sed ankaŭ povas esti sugesto.
Oni povus fari interesajn studojn sur tiu materialo.
Mi pensas pri aŭtomata kreado de vortaro.
Planoj (TODO)
Nun ekzistas multaj punktoj en programo, kiujn mi volas plibonigi. Mi rimarkis, ke mankas kelkaj funkcioj. Ekzemplo markilo por statuso de tradukado („akceptita“).
Fina vorto
Mi esperas, ke kelkaj homoj uzos Esperantilon por tradukado de programaro.